




Artificial intelligence is the use of computers to make automated decisions or predictions. Rather than a single technology, AI is a category of them, including technologies and applications that are so commonplace they’re rarely referred to as AI or AI-reliant, such as search engines, spam filters, credit ratings, weather forecasting, and certain kinds of election polling. Other applications are so novel they can seem magical. But even the most cutting-edge AI systems come from incremental gains in the same lineage of tools. All these computer functions rely on algorithms to interpret data and, based on inference, make automated decisions or predictions.
The most common uses for AI include:
Although AI systems are improving, their capabilities—or media reports about them—sometimes convey the illusion of broader skills, or a more humanlike consciousness, than is warranted. A modern AI system can’t reason the way a person would. It can identify a face without recognizing the person emotionally, as a friend might, or diagnose retinopathy without understanding what blindness means, as an occupational therapist might. On a basic level, AI is only, and always, processing numerical values.
Nonetheless, advances in AI have accelerated in recent years, due largely to two trends: more data and an improved ability to process it. Mobile devices have outnumbered people since 2014, and daily they are used to generate or share an increasing amount of text, sound, images, maps, and financial transactions. Advancements in computer hardware have led to faster processors and cheaper, more abundant digital storage. Together, these trends mean bigger data sets and increasingly efficient processes for training larger algorithms. As a result, AI technologies have improved, and more organizations have been able to implement them.
Today’s AI systems fall into two categories: rule-based and machine learning.
Rule-based systems, also called expert systems, follow specific instructions. These require developers to manually define every potential variable and outcome. The system then interprets human input, such as questions posed by a user, by matching that input with relevant instructions. Its steps are clearly laid out to follow the same logic a human expert would follow. Such a system can be used to test a vehicle or machine for faults, based on rules from mechanics; or to yield a medical diagnosis based on symptoms and blood-test results based on rules from clinicians.
A rule-based system can also act as an email spam filter. In this case, developers provide it with a list of words or phrases that suggest spam, or of addresses known to send spam, or some combination thereof. A more advanced rule-based system might include more rules, or might use rules to assign a “score” to every email to show the likelihood it is spam, with a certain score required for each email to pass into the inbox. Still, the computer only considers rules that are defined by humans.
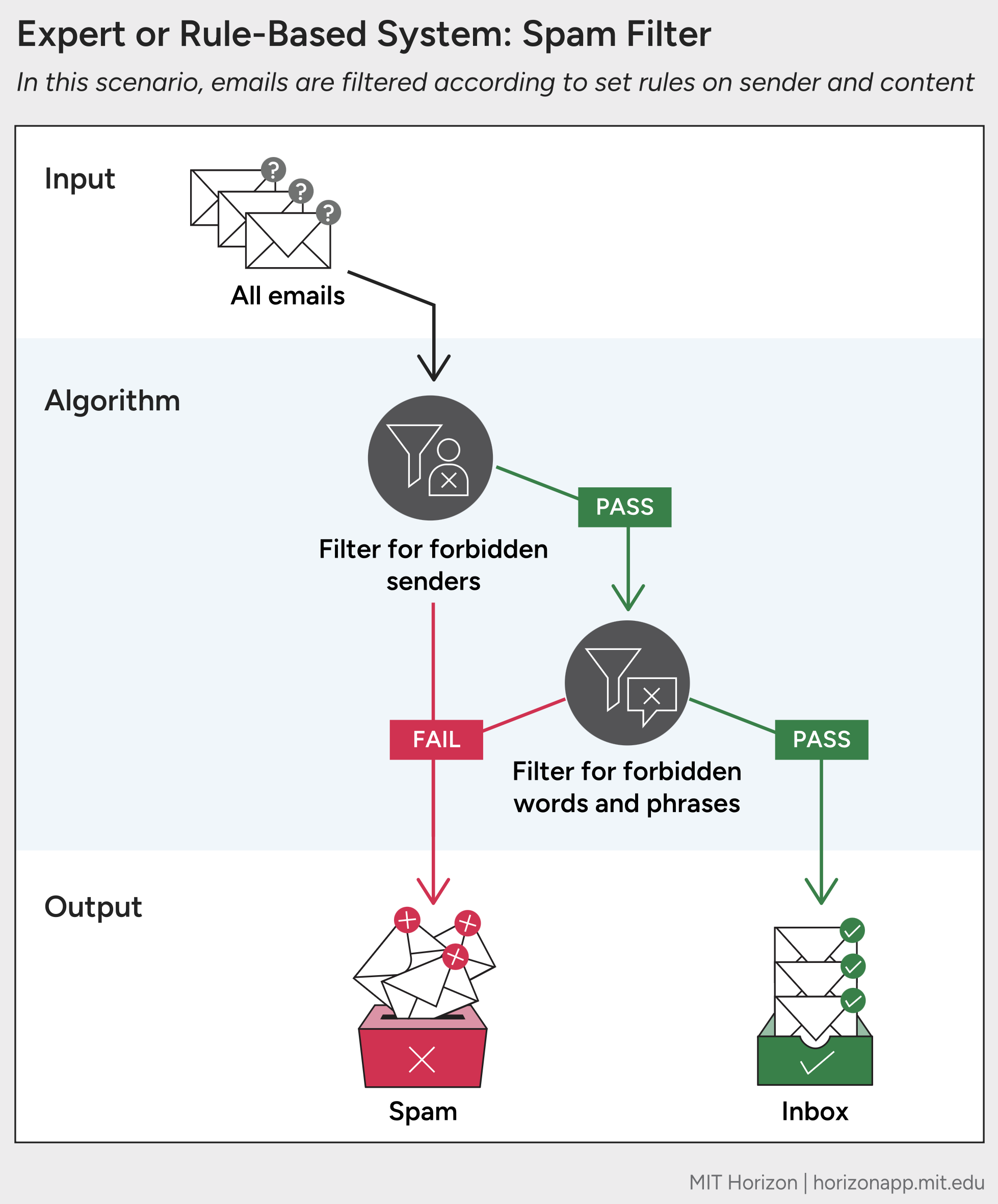
Rule-based systems have been in use for decades. However, they cannot accommodate new or unfamiliar information unless human developers update them manually.
Since the 1990s, most AI research, development, and adoption have been driven by machine learning. Rather than follow instructions from human developers, a machine learning system can learn from examples. It does not wholly depend on preprogrammed rules. Provided a goal and many examples of a task or event, its algorithms learn patterns and apply them.
The process of an AI system learning from examples is called training, and the system requires data to train on. A system meant to read handwritten numbers must be shown many images of numbers. One meant to predict housing prices must be shown many examples of homes and their sale prices. A machine learning system typically requires thousands of examples, or more, for its training.
At the start of its training, a machine learning system will perform no better than random chance. However, with each new data point, the system adjusts to reflect the patterns it sees. Over the course of training on many examples, the system learns to perform more accurately.
A variety of training approaches exist within machine learning. Most of the recent advances in AI have been their result. The approaches are useful when a task cannot easily be broken down into specific rules—a task like processing images, or understanding language, or playing a complex game.
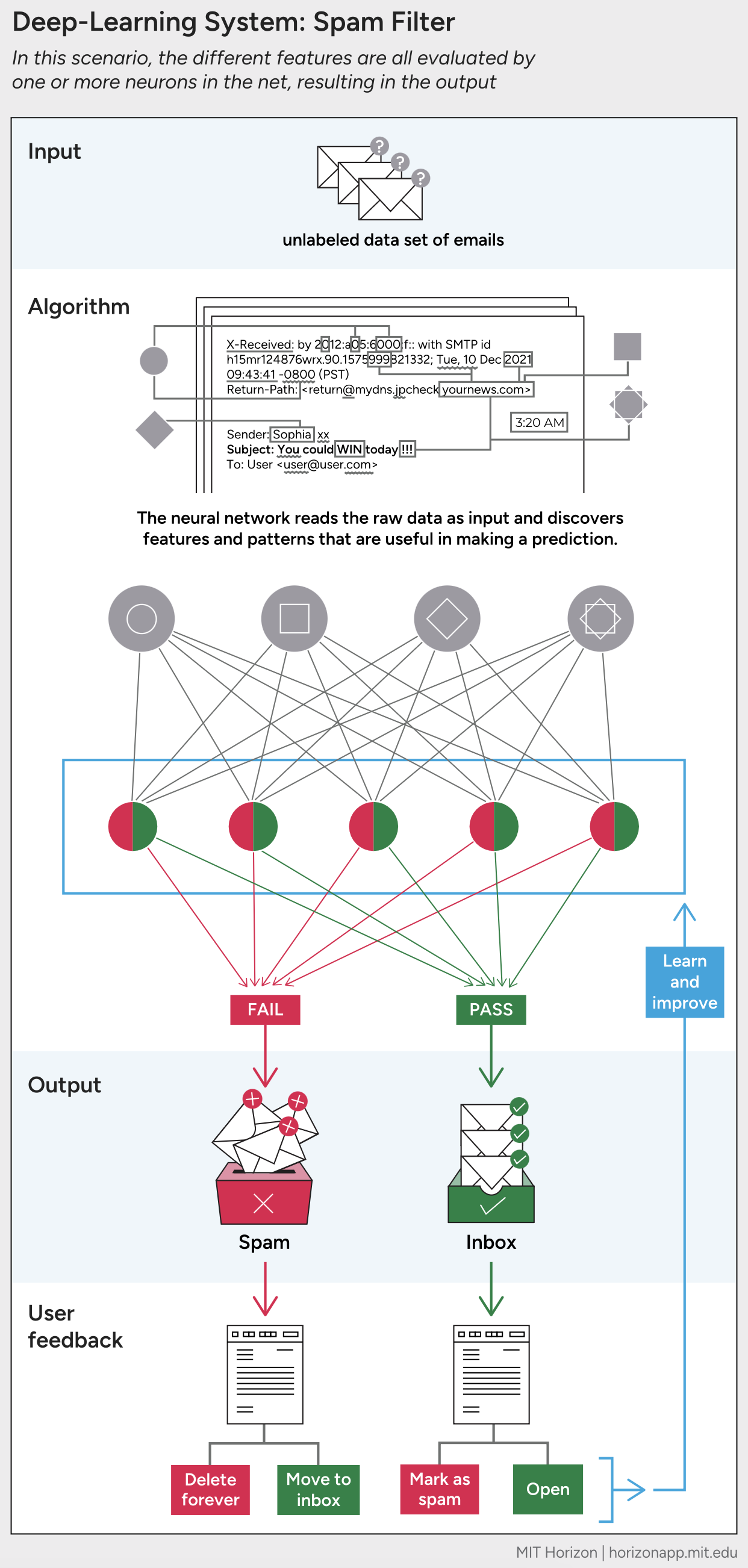
A spam filter trained by machine learning can catch spam that humans might not—by finding subtler patterns among more emails than a human developer would (or could) code for. Machine learning also allows a spam filter to adapt to changing circumstances, to keep up with spammer tactics, and to personalize its decisions for a particular inbox, based on feedback. Such a system might consider thousands of variables in a single email.

A machine learning system can be trained in any of three ways.
In supervised learning, an AI system is trained on data that a human developer has organized and described. (This sort of data is known as labeled, as a human has tagged its relevant features.) The system is also provided in advance with its potential conclusions. A system that distinguishes cars or pedestrians on a busy street, for example, must be trained on many images of streets with objects and people identified. It must also know that, when presented with real-life images at the end of its training, its conclusion must be “car” or “pedestrian.” A system that predicts condo prices must be trained on many postings that identify address, square footage, cost, and so on. It must also know that its eventual output, when presented with a real condo, will be a price. This sort of training is supervised in the sense that a human shapes how the computer interprets information, and for what purpose.
Supervised learning is used most often for classification or regression tasks.
The rephrasing of a question may change it subtly from a classification to regression task. “Is this email spam?” is a classification problem. “How much spam am I likely to get next month?” is a regression problem.
In unsupervised learning, an AI system is trained on data that no human has organized or described. (That is, unlabeled data.) Nor do developers define in advance the potential conclusions. Instead, the system is asked to discover for itself what patterns the data contains. Once developers provide it with many unlabeled examples, the system can use them as a basis for groupings. The computer, rather than human developers, invents those groupings. This sort of training is unsupervised in the sense that a human gives the computer relatively little guidance on how to interpret information.
A system trained this way might arrange customers into categories by similar behavior, or group patients based on their medical symptoms, or show what products customers often purchase together.
It’s unlikely that unsupervised learning would be used to train a spam filter, since spam email is already a knowable, easily labeled category. But an unsupervised model could be used to sort emails within an inbox into categories or to distinguish between types of spam (credit offers, promotion deals, scams, or unwanted newsletters) using keywords and address domains.
In reinforcement learning, a developer gives potential conclusions. (Like in supervised learning.) The system is trained on partially labeled data. (Unlike in supervised or unsupervised learning.) However, the defining characteristic is something else: that the system must learn to make decisions over time.
Reinforcement learning is common in gaming, where each player’s turn represents an opportunity for a new decision, in fresh circumstances. In this scenario, the computer must consider not just the effect of a single decision in a single turn but the effect of many decisions over many turns, all related. It is learning not just from individual instances but from sequences. In gameplay, feedback for such sequences is easy to gather: The computer wins or loses, gains points or fails to do so. Its choices are rewarded or penalized, one after another. (In other words, those choices are reinforced or not.) Through trial and error, over many sequences, it adjusts to achieve the long-term goal.
A system might be trained this way to adapt the curriculum of an online course in a manner that corresponds with the most students passing the final exam. It might guide dynamic pricing for an online vendor by identifying what price corresponds with the most purchases, or the highest profits. Or it might learn to play Go by competing with an opponent—either a human or another machine—many times.
It’s unlikely that reinforcement learning would be used to train a spam filter. (Supervised learning is still the best fit, as spam filtering is really a classification task.) But theoretically, a reinforcement model could be used to customize a spam filter over time.
Several important AI applications—including facial recognition, language translation, and guiding autonomous vehicles—depend on a class of machine learning that can handle very complex data sets. To interpret the patterns and interactions inside so much data requires algorithms with many mathematical units, working interdependently. Once a developer provides instructions, the AI system combines and weights those units proportionally. The resulting outputs form the inputs of an additional layer of mathematical units. Again the computer combines and weights them proportionally, for a subsequent output. And so on, with the output of one step yielding the input of the next. This pattern continues until the final layer, which yields a final output. In this scenario, each mathematical unit is called a neuron. The result is a neural network—literally, a network of neurons.
Typically, the more layers a neural network has, the more complexity it can accommodate. A simple network has just three layers—one for input, where the computer receives data; a second for calculating, where it does math; and a third for output, where it supplies its conclusions. The activity of a neural network with many layers is called deep learning, and it can discover very subtle, nuanced, and complex patterns in huge amounts of varied data. As organizations build increasingly larger and more sophisticated AI systems, engineers become more reliant on deep learning techniques. For example, to create text and imagery, ChatGPT and other generative AI systems use deep learning to draw associations between billions of documents and pictures at the letter and pixel level.
A telling example of how AI can improve at a task through more advanced training and on larger networks is facial recognition. The first computer algorithms for detecting objects were developed in the early 1980s. These followed specific rules from developers, often to compare pixels. By 1998, improved hardware and larger data sets allowed algorithms to identify whole features—such as eyes, ears, a nose, or a chin. Today, deep learning facial recognition systems do not require even that. Developers simply show a system many examples of faces. Over time, the system learns their crucial features, and in what order to best consider them. (This is an instance of deep, unsupervised learning.)
The result is facial recognition software that’s more accurate than any that human developers could program themselves—but that works more mysteriously. Because the process was designed partly by a computer, a human cannot easily retrace it. If a deep learning system fails—in recognizing the faces wearing hats or sunglasses or, more crucially, of people of color—a developer cannot easily adjust it. Instead, she might supply it with more examples of the underrepresented group in retraining data. Ideally, the AI system will learn to accommodate them. But when developers cannot see into an AI process, they cannot explain why it has reached a given outcome, predict in what conditions it will struggle, or repair it easily. This difficulty is perhaps the largest disadvantage of deep learning. It is not the only one. The power of neural networks comes at a cost. They are also relatively slow to train and to scale, and can demand huge energy expenses to do so.





